그래프에서 인접한 노드중에 적어도 하나의 노드에 감시카메라가 설치되어있지 않으면 해당 노드에 감시카메라를 설치 해야한다.
이때 필요한 최소한의 감시카메라의 개수를 구하는 문제이다.
문제 조건에서 "미술관은 한 번 관람한 갤러리를 다시 가기 위해서는 이전에 지나왔던 복도를 반드시 한 번 지나야 하는 구조로 설계되어 있으며"가 있으므로 해당 그래프는 트리형태임을 알 수 있다.
따라서 자손 노드들의 상태를 보고 하나라도 UNWATCHED상태라면 해당 노드에 감시카메라를 설치하는 알고리즘을 사용할 수 있다.
또한 "모든 갤러리가 서로 연결되어 있지 않을 수도 있습니다."라는 조건이 있으므로 모든 노드가 방문되었는지 확인하는 절차도 필요하다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
입력으로 주어지는 특정한 문자열 패턴들이 나타나지 않게 알파벳 소문자로만 이뤄진 n자리 암호를 만들 수 있는 모든 경우의 수를 10007로 나눈 나머지를 구하는 문제이다.
bruteforce로 풀게되면 26^n의 시간복잡도를 가지게 되므로 제한시간 안에 문제를 푸는것이 불가하다.
동적계획법을 이용하면 문제를 풀 수 있는데 그 방법이 매우 어렵고 까다롭다. (종만북의 연습문제중 가장 어려웠던것 같다.)
먼저 입력으로 주어진 문자열 패턴들을 트라이로 만들고 각 노드마다 상태를 부여한다.
앞으로 만들어야하는 글자의 갯수 length, 현재 트라이의 상태를 state라 했을때 cache[length][state]형태의 캐시를 이용한다.
하지만 이렇게 트라이를 이용한 동적계획법을 구현하기 위해서는
먼저 트라이의 각 노드들이 실패연결과 출력문자열을 가지고 있어야하고, 각 노드마다 상태 번호가 부여되야 한다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
L개의 알파벳이 주어졌을때 L개중 C개를 다음 조건에 맞게 골라 나열하여 출력하는 문제이다.
조건은 C개의 알파벳을 나열한 문자열은 알파벳순으로 정렬되 있어야 하고 모음이 한 개 이상 자음이 두 개 이상이여야 한다.
L개의 문자들을 알파벳 순으로 정렬한후 순서대로 조합하는 방식으로 문제를 해결 할 수 있다.
이때 완성된 암호의 모음의 갯수와 자음의 갯수를 확인하는 유효성 검사가 출력전에 선행되야 한다.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
뒤집기 함수인 R과 배열의 첫번째 요소를 버리는 함수 D를 조합해서 문자열의 형태로 입력에 주어지고 배열이 주어졌을때 함수의 조합들을 실행한후의 배열을 형태를 출력하는 문제이다.
문제에 주어진 조건에 맞게 입력과 출력을 해야하기 때문에 입출력 처리과정이 별도로 필요했다.
또한 R을 수행할때 배열을 직접 뒤질을 필요없이 deque를 이용하여 R이 짝수번 출현한 후의 D들은 deque.pop_front를,
R이 홀수번 출현한 후의 D들은 deque.pop_back으로 D를 수행하면 됐다.
출력시에 deque.size함수를 이용하였는데 deque의 사이즈가 0일시에는 deque.size()-1이 정상적으로 수행되지 않아
별도의 예외처리가 필요했다.(사실 이부분에서 몇시간을 해맸다....)
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Make zip file에서는 빌드한 파일을 압축하는 작업을 실행한다. S3 버킷에 파일을 올리기 위해서는 해당 작업이 선행되어야 한다.
이때 $GITHUB_SHA는 커밋의 해쉬값으로 해당 작업에서 workflow가 진행하는 커밋의 해쉬값을 파일명으로 하는 압축파일을 만든다는것을 의미한다.
다음으로 Configure AWS credentials는 IAM에서 추가한 사용자의 액세스 키 정보를 통해 S3에 접근권한을 받아오기 위한 작업이다.
이때 ${{SECRETS.~}}는 github의 해당 리포지토리의 setting에서 Secrets설정한 값을 읽어 온다.
따라서 해당 작업을 위해서는 github에 IAM 사용자 추가에서 나온 액세스 키 정보들을 등록해야한다.
다음 설정들을 모두 끝낸후 Github Actions를 돌리면 S3 버킷에 zip파일이 담긴것을 AWS console를 통해 확인할 수 있다.
다음으로 CodeDeploy 설정을 해야한다.
CodeDeploy를 작동시키기 위해서는 먼저 Github Actions이 참조하는 workflow의 main.yml파일에 CodeDeploy를 통해 배포하기 위한 명령어를 추가하고,
프로젝트 최상단에 AppSpec.yml파일을 추가한다.
AppSpec.yml은 각 배포단계에서 어떤 스크립트를 실행시킬지 적어놓은 명세서라고 할 수 있다.
GithubActions는 main.yml에 추가한 명령어를 통해 AWS의 CodeDeploy에 배포 요청을 보내고
CodeDeploy는 EC2에 설치되어있는 CodeDeployAgent에게 배포 명령을 내린다.
배포명령을 받은 Agent들은 깃허브에 저장되있는 프로젝트 전체를 서버에 내려받고 appspec.yml파일을 읽어 알맞은 스크립트를 실행시켜 배포를 진행한다.
CodeDeployAgent는 배포 성공 여부를 CodeDeploy에 알려주기 때문에 AWS console의 CodeDeploy에서 배포 성공여부를 확인할 수 있다.
이제 본격적으로 CodeDeploy설정을 해보겠다.
먼저 EC2에 CodeDeployAgent를 설치하여한다. EC2에 자바를 설치되어있다고 가정하고 다음 명령어들을 치면 된다.
# 패키지 매니저 업데이트, ruby설치
sudo apt-get update
sudo apt-get install ruby
sudo apt-get install wget
# 만약 서울리전에 있는 CodeDeploy 리소스 키트 파일을 다운받고 싶다면# wget https://aws-codedeploy-ap-northeast-2.s3.ap-northeast-2.amazonaws.com/latest/installcd /home/ec2-user
wget https://bucket-name.s3.region-identifier.amazonaws.com/latest/install
# 해당 파일에 실행 권한 부여
chmod +x ./install
# 설치 진행 및 Agnet 상태확인
sudo ./install auto
sudo service codedeploy-agent status
공식문서에서는 CodeDeployAgent를 설치하는 과정에서 apt-get대신 yum를 사용하는데 이것은 Linux가 어떤 계열인지에 따라 달라진다.
현재 사용중인 Linux가 레드헷 계열이라면 yum을 사용하고 우분투, 데비안계열이라면 apt-get를 사용해야한다.
나는 우분투 계열의 Linux를 사용중이기 때문에 yum대신 apt-get를 사용하였다.
이제는 EC2가 S3와 CodeDeploy에 대한 접근권한을 얻기 위해 IAM역할을 부여해야 한다.
위에서 GithubActions가 AWS의 S3에 접근하기위해 IAM사용자를 추가했었다.
IAM에대해 부연설명 하자면, GithubActions같이 외부에서 AWS의 접근 권한을 얻기 위해서는 IAM사용자를 추가해야하고,
EC2처럼 AWS에서 제공하는 서비스가 AWS내부 서비스에 접근하기 위해서는 IAM역할을 추가해줘야 한다.
역할 만들기에 들어가 사용 사례에서 EC2를 선택하고, AmazonS3FullAccess와 AWSCodeDeployFullAccess 정책을 추가한다.
역할을 성공적으로 생성했다면 EC2대시보드에 들어가 해당 EC2에 생성한 IAM역할을 부여한다.
다음으로 CodeDeploy에도 IAM역할을 생성해서 부여해야 한다.
IAM 역할만들기에서 CodeDeploy를 선택하고 사용사례에서 CodeDeploy를 선택하여 넘어간다.
이제 CodeDeploy 애플리케이션을 생성해야한다.
AWS console에서 CodeDeploy-애플리케이션-애플리케이션생성 에서 EC2를 선택하고 진행한다.
배포그룹 생성에서는 서비스역할에는 방금전 생성한 CodeDeploy용 IAM역할을 입력하고 배포유형은 현재 위치를 선택한다.
@EntitypublicclassMember{
@Id@GeneratedValue@Column(name = "MEMBER_ID")private Long id;
@ManyToOne@JoinColumn(name = "TEAM_ID")private Team team;
private String username;
}
@EntitypublicclassTeam{
@Id@GeneratedValue@Column(name = "TEAM_ID")private Long id;
private String name;
}
여기서 Team 객체를 통해서도 Member와의 관계를 알고 싶으면 양방향 연관관계를 걸어주면 된다.
다대일 양방향 연관관계를 나타내는 다이어그램과 코드는 다음과 같다.
@EntitypublicclassMember{
@Id@GeneratedValue@Column(name = "MEMBER_ID")private Long id;
@ManyToOne@JoinColumn(name = "TEAM_ID")private Team team;
private String username;
}
@EntitypublicclassTeam{
@Id@GeneratedValue@Column(name = "TEAM_ID")private Long id;
@OneToMany(mappedBy = "team")private List<Member> members = new ArrayList<>();
private String name;
}
외래키가 있는 쪽이 연관관계의 주인이므로 Member가 연관관계의 주인이 된다.
코드를 보면 다대일 단방향 연관관계에서 Team에 @OneToMany로 member를 노드로 하는 List를 추가하기만 하면 되는것을 알 수 있다.
여기서 @OneToMany에 mappedBy로 연관관계의 주인인 Member의 team를 지정해 주면 된다.
다음으로 일대다 연관관계가 있다.
일대다는 일과 다 중에 일이 연관관계의 주인일때를 말한다. 하지만 테이블에서는 일대다 관계에서 항상 다 쪽에 외래키가 있다.
즉 일대다 연관관계에서는 연관관계의 주인이 반대편 테이블의 외래키를 관리하는 특이한 구조를 갖게 된다.
이때, 주의할 점은 @OneToMany를 사용할때 @JoinColumn을 꼭 사용해야 한다는 것이다. 그렇지 않으면 조인 테이블 방식이 디폴트로 적용되는데 이것은 중간에 테이블을 하나 추가하는 방식으로써 의도치 않은 테이블의 생성으로 인한 테이블 관리의 불편함이 생길 수 있다.
일대다 단방향 연관관계를 나타내는 다이어그램과 코드는 다음과 같다.
@EntitypublicclassMember{
@Id@GeneratedValue@Column(name = "MEMBER_ID")private Long id;
private String username;
}
@EntitypublicclassTeam{
@Id@GeneratedValue@Column(name = "TEAM_ID")private Long id;
@OneToMany@JoinColumn(name = "TEAM_ID")private List<Member> members = new ArrayList<>();
private String name;
}
일대다 단방향 매핑은 엔티티가 관리하는 외래키가 다른 테이블에 있어서 jpa를 통해 테이블을 다루는거 자체가 쉽지않다.
예를들어 team.setMembers같은 메서드를 쓸때 TEAM 테이블이 아닌 MEMBER 테이블에 update쿼리가 나가는등 코드의 일부분만 봐서는 쿼리 예측이 쉽지 않게 된다.
따라서 대다수의 경우에 일대다 단방향 매핑보다는 다대일 양방향 매핑을 사용하는게 바람직하다.
일대다 양방향 매핑은 공식적으로 존재하지 않지만 @JoinColumn(insertable = false, updatable = false)를 이용하여 일대다 양방향 매핑을 구현할 수 있다.
일대다 양방향 매핑을 나타내는 다이어그램과 코드는 다음과 같다.
@EntitypublicclassMember{
@Id@GeneratedValue@Column(name = "MEMBER_ID")private Long id;
@ManyToOne@JoinColumn(name = "TEAM_ID", insertable = false, updatable = false)private Team team;
private String username;
}
@EntitypublicclassTeam{
@Id@GeneratedValue@Column(name = "TEAM_ID")private Long id;
@OneToMany@JoinColumn(name = "TEAM_ID")private List<Member> members = new ArrayList<>();
private String name;
}
하지만 일대다 양방향 매핑 또한 대부분의 경우 다대일 양방향을 사용하여 해결할 수 있으므로 관리가 비교적 어려운 일대다 매핑보다는
구현이 용이하고 관리가 직관적인 다대일 양방향 매핑을 사용하는것이 바람직하다.
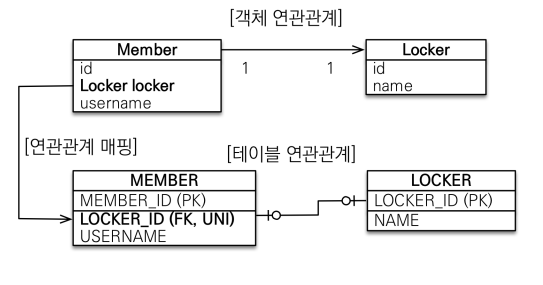
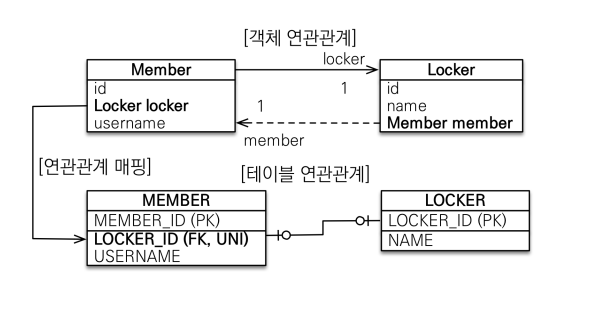
다음으로 일대일 연관관계가 있다.
일대일 연관관계에서는 주 테이블이나 대상 테이블 중에 외래키를 어디다 둘지 선택 가능하다.
예를들어 한명(MEMBER)당 최대 하나의 사물함(LOCKER)을 배정 받을 수 있다 했을때 MEMBER 테이블을 주 테이블, LOCKER테이블을 대상 테이블이라고 하자.