관계형 데이터베이스는 상속관계가 따로있지는 않지만 데이터베이스의 슈퍼타입 서브타입 관계라는 모델링 기법이 객체 상속과 유사하다.
상속관계 매핑이란 객체의 상속 구조와 DB의 슈퍼타입 서브타입관계를 매핑하는것을 말한다.
상속관계 매핑에는 3가지 방법이 존재한다.
각각 테이블로 변환 -> 조인 전략
통합 테이블로 변환 -> 단일 테이블 전략
서브타입 테이블로 변환 -> 구현 클래스마다 테이블 전략
먼저 조인 전략을 다이어그램과 코드로 표현하면 다음과 같다.
@Entity
@Inheritance(strategy = InheritanceType.JOINED)
@DiscriminatorColumn // 서브타입을 나타내는 속성값이 테이블에 추가됨
public class Item {
@Id @GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
public class Album extends Item {
private String artist;
}
@Entity
public class Movie extends Item {
private String director;
private String actor;
}
@Entity
public class Book extends Item {
private String author;
private int isbn;
}
하지만 조회시 조인을 많이 사용하여 성능이 저하되고, 조회 쿼리가 복잡하며, 데이터 저장시 insert 쿼리가 2번 호출된다.
다음으로 단일 테이블 전략이 있다.
단일 테이블 전략은 자식 엔티티의 모든 속성들을 부모 테이블에 몰아넣는 방식으로 상속관계를 구현한다.
단일 테이블 전략을 표현하는 다이어그램과 코드는 다음과 같다.
@Entity
@Inheritance(strategy = InheritanceType.SINGLE_TABLE)
@DiscriminatorColumn // 없어도 DTYPE속성 생김
public class Item {
@Id @GeneratedValue
private Long id;
private String name;
private int price;
}
@Entity
public class Album extends Item {
private String artist;
}
@Entity
public class Movie extends Item {
private String director;
private String actor;
}
@Entity
public class Book extends Item {
private String author;
private int isbn;
}
단일 테이블 전략은 조인이 필요 없으므로 일반적으로 조회 성능이 빠르고 조회 쿼리 또한 단순하다.
반면 자식 엔티티가 매핑한 컬럼은 모두 null을 허용해야 하며, 단일 테이블이 커져 조회성능이 오히려 느려질 수 있다.
마지막으로 구현 클래스마다 테이블 전략이 있는데, 여러 자식 테이블을 함께 조회할 때 성능이 느리고 자식 테이블을 통합해서 쿼리하기 어렵다.
이러한 단점들로 인해 해당 전략은 데이터베이스 설계자와 ORM 전문가 양쪽다 사용하기 꺼려하므로 대부분의 경우 사용하지 않는것이 바람직하다.
다음으로 설명할것은 @MappedSuperclass이다.
@MappedSuperclass는 공통 매핑 정보가 필요할 때 사용된다.
예를들어 대부분의 엔티티에 해당 객체가 만들어진 날짜(craetedDate)와 마지막 수정 날짜(lastModifiedBy)가 공통적으로 들어간다고 해보자.
이 경우 엔티티 하나하나마다 공통 필드를 추가하는것보다 추상클래스를 만들어 상속하는 식으로 구현하는것이 훨씬 효율적이다.
여기서 추상클래스 역할을 하는것에 @MappedSuperclass를 사용하면 된다.
@MappedSuperclass를 구현하는 코드는 다음과 같다.
@MappedSuperclass
public abstract class BaseEntity {
private LocalDateTime createdDate;
private LocalDateTime lastModifiedDate;
... // get set 구현
}
@Entity
public class otherEntity extends BaseEntity {
...
}
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
private String username;
}
@Entity
public class Team{
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
private String name;
}
여기서 Team 객체를 통해서도 Member와의 관계를 알고 싶으면 양방향 연관관계를 걸어주면 된다.
다대일 양방향 연관관계를 나타내는 다이어그램과 코드는 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
private String username;
}
@Entity
public class Team{
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
private String name;
}
외래키가 있는 쪽이 연관관계의 주인이므로 Member가 연관관계의 주인이 된다.
코드를 보면 다대일 단방향 연관관계에서 Team에 @OneToMany로 member를 노드로 하는 List를 추가하기만 하면 되는것을 알 수 있다.
여기서 @OneToMany에 mappedBy로 연관관계의 주인인 Member의 team를 지정해 주면 된다.
다음으로 일대다 연관관계가 있다.
일대다는 일과 다 중에 일이 연관관계의 주인일때를 말한다. 하지만 테이블에서는 일대다 관계에서 항상 다 쪽에 외래키가 있다.
즉 일대다 연관관계에서는 연관관계의 주인이 반대편 테이블의 외래키를 관리하는 특이한 구조를 갖게 된다.
이때, 주의할 점은 @OneToMany를 사용할때 @JoinColumn을 꼭 사용해야 한다는 것이다. 그렇지 않으면 조인 테이블 방식이 디폴트로 적용되는데 이것은 중간에 테이블을 하나 추가하는 방식으로써 의도치 않은 테이블의 생성으로 인한 테이블 관리의 불편함이 생길 수 있다.
일대다 단방향 연관관계를 나타내는 다이어그램과 코드는 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
private String username;
}
@Entity
public class Team{
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
@OneToMany
@JoinColumn(name = "TEAM_ID")
private List<Member> members = new ArrayList<>();
private String name;
}
일대다 단방향 매핑은 엔티티가 관리하는 외래키가 다른 테이블에 있어서 jpa를 통해 테이블을 다루는거 자체가 쉽지않다.
예를들어 team.setMembers같은 메서드를 쓸때 TEAM 테이블이 아닌 MEMBER 테이블에 update쿼리가 나가는등 코드의 일부분만 봐서는 쿼리 예측이 쉽지 않게 된다.
따라서 대다수의 경우에 일대다 단방향 매핑보다는 다대일 양방향 매핑을 사용하는게 바람직하다.
일대다 양방향 매핑은 공식적으로 존재하지 않지만 @JoinColumn(insertable = false, updatable = false)를 이용하여 일대다 양방향 매핑을 구현할 수 있다.
일대다 양방향 매핑을 나타내는 다이어그램과 코드는 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@ManyToOne
@JoinColumn(name = "TEAM_ID", insertable = false, updatable = false)
private Team team;
private String username;
}
@Entity
public class Team{
@Id @GeneratedValue
@Column(name = "TEAM_ID")
private Long id;
@OneToMany
@JoinColumn(name = "TEAM_ID")
private List<Member> members = new ArrayList<>();
private String name;
}
하지만 일대다 양방향 매핑 또한 대부분의 경우 다대일 양방향을 사용하여 해결할 수 있으므로 관리가 비교적 어려운 일대다 매핑보다는
구현이 용이하고 관리가 직관적인 다대일 양방향 매핑을 사용하는것이 바람직하다.
다음으로 일대일 연관관계가 있다.
일대일 연관관계에서는 주 테이블이나 대상 테이블 중에 외래키를 어디다 둘지 선택 가능하다.
예를들어 한명(MEMBER)당 최대 하나의 사물함(LOCKER)을 배정 받을 수 있다 했을때 MEMBER 테이블을 주 테이블, LOCKER테이블을 대상 테이블이라고 하자.
주 테이블에 외래키가 있는 단방향 매핑을 다이어그램과 코드로 보이면 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
private String username;
}
@Entity
public class Locker {
@Id @GeneratedValue
@Column(name = "LOCKER_ID")
private Long id;
private String name;
}
보다시피 다대일 단방향 매핑과 매우 유사한것을 알 수 있다. 때문에 여기서 양방향 매핑을 거는것 또한 다대일 양방향 매핑과 매우 유사하다.
일대일 연관관계에서 주 테이블에 외래키가 있는경우 양방향 매핑에 대한 다이어그램과 코드는 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
@Column(name = "MEMBER_ID")
private Long id;
@OneToOne
@JoinColumn(name = "LOCKER_ID")
private Locker locker;
private String username;
}
@Entity
public class Locker {
@Id @GeneratedValue
@Column(name = "LOCKER_ID")
private Long id;
@OneToOne(mappedBy = "locker")
private Member member;
private String name;
}
지금까지는 일대일 연관관계중에서도 주 테이블에 외래키가 있는 경우를 살펴보았다.
다음으로 대상 테이블에 외래키가 있는경우에 대해 말하고자 한다.
먼저 대상 테이블(LOCKER)에 외래키가 있는 경우 Member(Member.locker)를 연관관계의 주인으로 일대일 단방향 매핑을 하는 방법은 없다.
대상 테이블(LOCKER)에 외래키가 있는 경우 양방향 매핑은 가능하다.
단, 연관관계의 주인 또한 LOCKER(Locker.member)로 설정 해야하고, 따라서 Member는 읽기만 가능하다.
일대일 관계에서 주 테이블에 외래키가 있는경우 다음과 같은 특징이 있다.
주 객체가 대상 객체의 참조를 가지는것 처럼 주 테이블에 외래키를 두고 대상 테이블을 찾는다.
JPA 매핑이 편리하고 주 테이블만 조회해도 대상 테이블에 데이터가 있는지 확인 가능하므로 객체지향 개발자가 선호한다.
단점으로는 값이 없으면 외래키에 null값을 허용해야 한다.
일대일 관계에서 대상 테이블에 외래키가 있는경우 다음과 같은 특징이 있다.
대상 테이블에 외래키가 존재한다.
주 테이블과 대상 테이블을 일대일에서 일대다 관계로 변형할 때 테이블 구조를 유지할수 있어 전통적인 데이터베이스 개발자가 선호한다.
단점으로는 프록시 기능의 한계로 지연로딩으로 설정해줘도 즉시로딩이 불가피하다.
마지막으로 다대다 연관관계가 있다.
JPA에서 @ManyToMany를 사용한 다대다 매핑을 지원하지만 해당 관계에관한 다른 속성값을 추가할 수 없는 문제가 있다.
따라서 다대다 연관관계는 연결 테이블용 엔티티를 추가해서 다대일 일대다 관계로 풀어서 구현하는게 일반적이다.
예를 들어 고객(Member)과 상품(Product)이 다대다 관계라고 했을때, 고객과 상품사이에 MemberProduct라는 엔티티를 추가하여 각각 일대다 다대일 매핑을한다.
다대다 관계를 일대다 다대일 관계로 풀어서 매핑한 다이어그램과 코드는 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@OneToMany(mappedBy = "member")
private List<MemberProduct> memberProduct = new ArrayList<>();
private String username;
}
@Entity
public class Product{
@Id @GeneratedValue
private Long id;
@OneToMany(mappedBy = "product")
private List<MemberProduct> memberProduct = new ArrayList<>();
private String name;
}
@Entity
public class MemberProduct {
@Id @GeneratedValue
private Long id;
@ManyToOne
@JoinColumn(name = "MEMBER_ID")
private Member member;
@ManyToOne
@JoinColumn(name = "PRODUCT_ID")
private Product product;
private int orderAmount;
private int orderDate
}
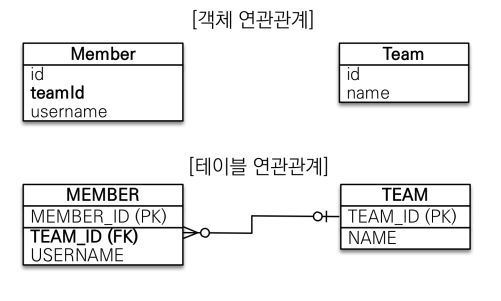
회원과 팀이 있고 회원은 하나의 팀에만 소속될 수 있다고 하자. 즉, 회원과 팀은 다대일 관계이다.
먼저 객체를 테이블에 맞춰 모델링 하면 다음과 같다.
위 그림에서 MEMBER테이블에는 TEAM_ID라는 외래 키가 있고, Member객체에는 teamId라는 필드가 있다. 이를 코드로 나타내면 다음과 같다.
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
@Column(name = "TEAM_ID")
private Long teamId;
}
@Entity
@Getter @Setter
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
}
이러한 엔티티를 저장하고 조회하는 방법은 다음과 같다.
//팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//회원 저장
Member member = new Member();
member.setName("member1");
member.setTeamId(team.getId());
em.persist(member);
//Member 조회
Member findMember = em.find(Member.class, member.getId());
//연관관계가 없음
Team findTeam = em.find(Team.class, team.getId());
테이블은 외래 키를 통해 조인연산을 하여 연관된 테이블을 찾는 반면, 객체는 참조를 사용해서 연관된 객체를 찾는다.
이처럼 관계형 데이터베이스의 테이블과 객체 사이에는 큰 간격이 있다.
우리는 연관관계 매핑을 통해 테이블과 객체 사이의 간격을 매울수 있다.
이제 연관관계를 사용한 객체 지향 모델링을 살펴보자.
위 그림처럼 테이블 연관관계에서는 MEMBER테이블에 TEAM_ID라는 외래키가 있고,
객체 연관관계에서는 Member객체에 Team객체를 참조하는 team필드가 있음을 알 수 있다.
이를 코드로 표현하면 다음과 같다.
@Entity
@Getter @Setter
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
}
@Entity
@Getter @Setter
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
}
여기서 @ManyToOne 어노테이션은 다대일(Member객체 입장에서 Team과의 관계) 매핑정보임을 나타낸다.
@JoinColumn은 외래키를 매핑 할 때 사용되는데, name은 매핑할 외래키의 이름을 지정한다.
이런식으로 엔티티를 설계한 경우 저장, 조회, 수정하는 코드는 다음과 같다.
// 팀 저장
Team team = new Team();
team.setName("TeamA");
em.persist(team);
//회원 저장
Member member = new Member();
member.setName("member1");
member.setTeam(team); //단방향 연관관계 설정, 참조 저장
em.persist(member);
//조회
Member findMember = em.find(Member.class, member.getId());
//참조를 사용해서 연관관계 조회
Team findTeam = findMember.getTeam();
// 새로운 팀B
Team teamB = new Team();
teamB.setName("TeamB");
em.persist(teamB);
// 회원1에 새로운 팀B 설정
member.setTeam(teamB);
이 시점에서 우리는 방향(단방향, 양방향)에 대해 얘기할 수 있다.
관계형 데이터베이스의 경우 외래키만으로 두 테이블의 관계를 나타낼 수 있다. 하지만 우리는 앞서 말했듯이 연관관계를 이용한 객체 지향 모델링을 하고자 한다.
이 경우 두 엔티티 사이의 관계를 외래키(관계된 상대 테이블의 id값)가 아닌 상대 객체 자체를 참조하여 관계를 나타낸다.
이때 위에 엔티티를 정의한 코드에서처럼 Member 엔티티에만 Team객체를 참조하게 되면 단방향 연관관계라 하고
Team 엔티티에서는 자체적으로 자신에게 속한 Member들이 어떤것들이 있는지 알 수 없게 된다.
즉, 단방향 연관관계만으로는 team.getMembers()같은 코드를 구현할 수 없게 된다.
이를 해결하기 위해 등장한게 양방향 연관관계이다. 양방향 연관관계를 표현한 객체와 테이블 사이의 관계는 다음과 같다.
@Entity
public class Member {
@Id @GeneratedValue
private Long id;
@Column(name = "USERNAME")
private String name;
private int age;
@ManyToOne
@JoinColumn(name = "TEAM_ID")
private Team team;
...
}
@Entity
public class Team {
@Id @GeneratedValue
private Long id;
private String name;
@OneToMany(mappedBy = "team")
List<Member> members = new ArrayList<Member>();
...
}
단방향 연관관계와는 다르게 Team 엔티티에 List형태의 members필드가 추가된것을 확인할 수 있다.
이 필드를 통해 이제 Team에서도 어떤 Member들이 속해 있는지를 알 수 있게 된다.
하지만 양방향 연관관계에서는 주의해야할 점이 있다. 바로 연관관계의 주인을 정해야 하는것이다.
만약 Member 객체의 team필드를 수정하였지만 해당관계를 동일하게 나타내는 Team 객체의 members필드는 수정하지 않았다고 가정해보자.
이때 jpa는 수정을 반영해야할지 말아야할지 결정을 내려야만 한다. 때문에 연관관계의 주인이라는 개념이 필요하고
jpa는 연관관계의 주인인 쪽의 값을 반영하여 테이블을 관리하게 된다.
다르게 말하면 주인이 아닌쪽은 수정이 받아들여지지 않고 오직 읽기만 가능하다.
예를들어 Member가 Member와 Team사이 관계의 연관관계 주인이라면 team.getMembers().add(member)같은 코드는 데이터베이스에 반영되지 않는다.
연관관계의 주인을 정하는 방법은 간단하다. 외래 키가 있는 곳을 주인으로 정하면 된다.
위를 예시로 들면, Member와 Team사이의 관계에서 Member(Member.team)를 연관관계의 주인으로 하면 된다.
연관관계의 주인을 정했으면, 이제 연관관계의 주인만이 외래 키를 관리(등록, 수정)해야 한다.
주인이 아닌쪽은 읽기만 가능하며, mappedBy 속성으로 자신의 주인을 지정해 주면 된다.
양방향 연관관계에서 주의할 점은 연관관계를 나타내는 참조 값(Member의 team필드 또는 Team의 members필드)을 수정할때 양쪽 모두 수정해야 한다는 것이다.
그렇지 않으면 데이터베이스에서 받아오는 정보와 1차캐시에 있는 정보의 불일치가 일어나는등의 문제가 생길 수 있다.
영속성 컨텍스트에 대해 먼저 간단히 설명하자면 '엔티티를 영구 저장하는 환경' 이라는 뜻인데,
엔티티 메니저가 아래 코드와 같이 엔티티를 저장하거나 조회하면 영속성 컨텍스트는 엔티티를 보관/저장하여 관리하게 된다.
EntityManager.persist(entity);
영속성 컨텍스트에 대해 본격적으로 얘기하기 앞서 먼저 알아야 할것은 엔티티의 생명 주기이다.
엔티티의 생명주기를 코드와 함께 보면 다음과 같다.
비영속 (new/transient) : 영속성 컨텍스트와 전혀 관계가 없는 새로운 상태
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
영속 (managed) : 영속성 컨텍스트에 관리되는 상태
Member member = new Member();
member.setId("member1");
member.setUsername(“회원1”);
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
//객체를 저장한 상태(영속)
em.persist(member);
이제 엔티티의 생명주기가 어떤식으로 운영되는지, 또한 영속성 컨텍스트는 어떤식으로 동작하는지 얘기해보자.
맨 앞에서 영속성 컨텍스트란 엔티티객체를 관리해주는거라 간단히 말했는데 이렇게 영속성 컨텍스트를 이용하므로써 얻을 수 있는 이점은 다음과 같다.
1차 캐시
동일성(identity) 보장
트랜잭션을 지원하는 쓰기 지연 (transactional write-behind)
변경 감지(Dirty Checking)
지연 로딩(Lazy Loading)
먼저 1차 캐시를 가짐으로써 db와의 통신을 줄일 수 있다.
처음 엔티티 객체를 생성하게 되면 비영속 상태이고, 엔티티 객체와 영속 컨텍스트는 아래 그림처럼 아무런 관계가 없다.
비영속 상태의 엔티티 객체를 엔티티매니저를 통해 저장(em.persist)하면 아래 그림처럼 영속 켄텍스트가 1차 캐시를 통해 엔티티객체를 저장/관리 한다.
이렇게 영속 컨텍스트에 의해 관리되는 영속상태의 엔티티객체를 조회(em.find)할 경우 아래 그림처럼 db를 통하지 않고 영속 켄텍스트의 1차캐시를 통해 객체 정보를 받아온다.
영속 컨텍스트로 관리되고 있지 않는 비영속 상태 엔티티객체를 조회할 경우에는 아래 그림과 같이 작동한다.
다음 이점인 동일성 보장이란 1차 캐시에 있는 엔티티를 참조함으로써 == 연산을 가능하게 해준다는 뜻이다.
Member a = em.find(Member.class, "member1");
Member b = em.find(Member.class, "member1");
System.out.println(a == b); // 동일성 비교 true
만약 1차캐시가 있는 영속 컨텍스트를 이용하지 않는다면 db에 직접 정보를 받아와 각각의 객체에 할당해야하기 때문에 동일한 정보라도 ==연산을 하면 false가 나올것이다.
다음 이점으로 트랜잭션을 지원하는 쓰기 지연이 있다.
영속 컨텍스트에는 1차 캐시 말고도 '쓰기 지연 SQL 저장소'라는게 있다. 트랜잭셕이 시작하고 나서 에티티 매니저가 요청하는 INSERT 쿼리들은 바로바로 db로 넘어가는 것이 아니라 쓰기 지연 SQL 저장소에 저장 된다.
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
//엔티티 매니저는 데이터 변경시 트랜잭션을 시작해야 한다.
transaction.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다.
transaction.commit(); // [트랜잭션] 커밋
저장된 INSERT SQL 들은 트랜잭셕이 커밋되는 시점에 flush되서 db로 한꺼번에 넘어가게 된다.
다음 이점은 엔티티 수정 변경 감지(Dirty Checking)가 있다.
영속 컨텍스트는 1차캐시에 스냅샷이란것을 유지해서 flush되는 시점에 현재 엔티티객체의 상태와 1차캐시의 스냅샷에 저장된 엔티티객체의 상태를 비교하고 다르다면 UPDATE SQL을 생성하여 쓰기 지연 SQL 저장소에 등록 했다가 기존에 쓰기 지연 SQL 저장소에 등록돼 있었던 쿼리들과 함께 한꺼번에 db에 전송한다.
영속성 컨텍스트로 얻을 수 있는 이점으로 지연로딩이 남았는데, 이는 프록시와 관련되 있어서 프록시를 주제로 다룰때 따로 설명할 예정이다.
참고로 영속성 컨텍스트를 플러시 하는 방법으로는 아래와 같은 경우들이 있다.
em.flush() - 직접 호출
트랜잭션 커밋 - 플러시 자동 호출
JPQL 쿼리 실행 - 플러시 자동 호출
여기서 주의할 점은 플러시는 쓰기 지연 SQL 저장소에 있는 쿼리들을 db에 전송하는 것이지 영속성 컨텍스트를 비우는 것이 아니다.
영속성 컨텍스트를 완전히 초기화하기 위해서는 em.clear()라는 명령어가 쓰이고, 영속성 컨텍스트를 종료하기 위해서는 em.close()가 쓰인다.